Awat Feizi és professor del Departament de Biostatística i Epidemiologia de l’Escola de Salut de la Universitat de Ciències Mèdiques d’Isfahan, i membre del Centre de Recercar en Rehabilitació Cardíaca d’aquesta mateixa universitat. És l’autor corresponsal d’un article que apareix aquesta setmana a la revista BMC Medical Informatics and Decision Making en el que s’apliquen tècniques d’aprenentatge automàtic i d’estatística sobre dades de l’Estudi de Cohort d’Isfahan per elaborar una predicció de la incidència de malaltia cardiovascular. El primer autor de l’article és Kamran Mehrabani-Zeinabad, del Centre de Recerca Cardiovascular de la Universitat d’Isfahan. Desenvolupat entre el 1990 i el 2027, l’ICS inclou dades de 5.432 persones sanes, amb un seguiment mitjà de 16 anys. Mehrabani-Zeinabad et al. han aplicat un arbre de regressió additiva bayesiana BARTm sobre aquesta base de dades atenent a 515 variables. En altres algoritmes de classificació retenen únicament 49 variables que cobreixen més del 90% de la cohort. A través d’una tècnica d’eliminació de tret recursiu (RFE) han seleccionat les variables que tenen una major contribució en la predicció d’incidència de malaltia cardiovascular futura: l’edat, la pressió sanguínia sistòlica, la glucèmia en dejuni, la glucosa postprandial al cap de dues hores, la diabetes mellitus, un antecedent de malaltia cardíaca, un antecedent de pressió sanguínia alta i un antecedent de diabetis. L’anàlisi de discriminant quadràtic (QDA) és el més precís però també el menys sensible. Els arbres de decisió són els menys precisos, però els més sensibles. A mig camí queda BARTm.90%.
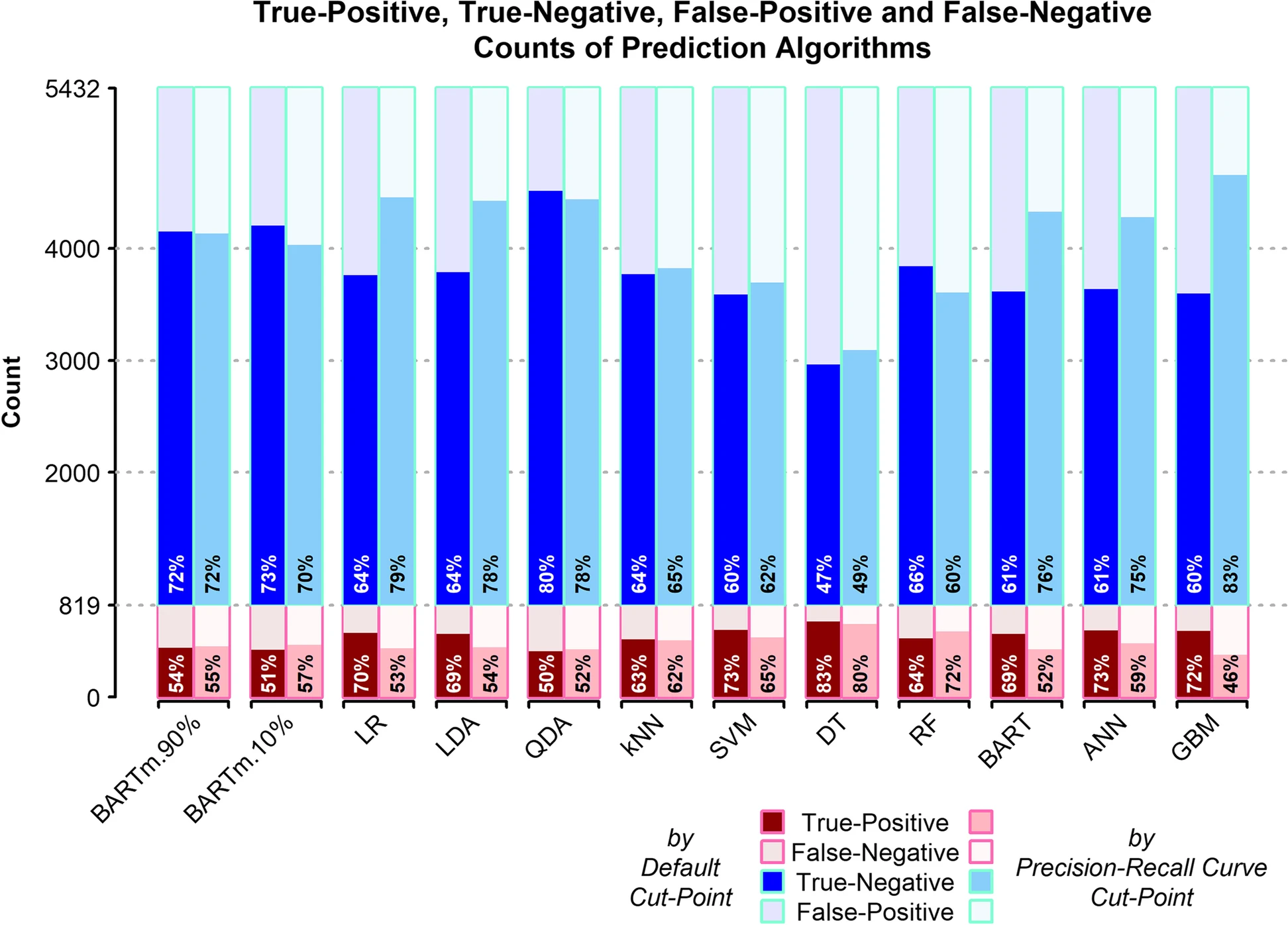
Precisió d’algoritmes de predicció emprats sobre l’ICS
Incidència i risc cardiovascular a Isfahan
Aquesta recerca fou concebuda per Feizi i Mehrabani. Les dades foren tractades per Mohammad Talaei (investigador del Wolfson Institute for Population Health, de la Queen Mary University of London), Masoumeh Sadeghi (investigadora del Centre de Recerca en Rehabilitació Cardíaca d’Isfahan), Hamidreza Roohafza (investigador del Centre de Recerca Cardiovascular d’Isfahan) i Mehrabani. L’anàlisi formal fou a càrrec de Mehrabani. La investigació la dugueren a terme Feizi i Mehrabani, que també dissenyaren la metodologia. Del programari se’n feia càrrec Mehrabani. La supervisió la feien Sadeghi i Feizi. La validació la feren Mehrabani i Sadeghi. Els gràfics foren realitzats per Feizi, Sadeghi i Roohafza.
Els autors tenen paraules d’agraïment per al personal de l’Estudi de Cohort d’Isfahan, i en particular per a Foad Souzani per posar-hi a disposició les dades de la cohort. L’article fou presentat a la revista el 19 de setembre del 2022. Després de cinc revisions, l’article fou acceptat el 4 d’abril del 2023 i publicat el dia 19.
L’Estudi de Cohort d’Isfahan fou promogut per l’Organització Mundial de la Salut. Des del 1980 la malaltia cardiovascular és la causa global principal de mortalitat. La mortalitat cardiovascular anual s’estima en 17,9 milions (el 32% de tota la mortalitat). Entre els factors de risc cardiovascular es distingeixen entre els no-modificables (edat, gènere, etnicitat, historial familiar) i els que sí ho són (pressió sanguínia alta, diabetes, dislipidèmia, obesitat, manca d’activitat física, dieta poc saludable, estrès i tabaquisme). Tota una línia d’investigació es dedica a determinar el pes d’aquests factors, bé a través de mètodes estatístics tradicionals com també de manera creixent per algoritmes d’aprenentatge automàtic. Entre els algoritmes més emprats amb aquesta finalitat hi ha els veïns més propers-k (KNN), la màquina de vector de suport (SVM), els arbres de decisió (DT), el bosc aleatori (RF), la xarxa neural artificial (ANN) i la màquina d’estímul de gradient (GBM).
L’Estudi de Cohort d’Isfahan en la seva versió actual s’inicià en el 2001, incloent-hi no tan sols participants d’Isfahan, sinó també de Najafabad i Arak. El període de recrutament anà del 2 de gener al 28 de setembre del 2001, i inclogué 6.323 participants seleccionats de mostratges aleatoris sobre la població general. Entre els criteris d’inclusió hi havia el d’ésser iranià, major de 35 anys, competent mentalment i que no es trobessin en gestació en aquell moment. Entre els criteris d’exclusió hi havia el d’haver partit accidents cardiovasculars. Dels 6.323 participants, hi ha dades d’almenys un seguiment de 5.432. En la primera visita els participants eren entrevistats per professionals sanitaris formats i se’n recollien dades en qüestionaris i llistats. Cada cinc anys, tots els participants tenien visites de seguiment amb un examen mèdic complet i extracció de mostres de sang. Dues vegades a l’any els participants eren avaluats amb una trucada telefònica per saber si havien patit certs esdeveniments predefinits.
Mehrabani-Zeinabad et al. es fixen en el període que va el 2001 al 2017. Es consideren les dades basals del 2001 com factors de risc potencial per a l’aparició d’esdeveniments de malaltia cardiovascular registrats fins el 2017. El protocol d’aquest estudi secundari fou revisat i aprovat pel comitè ètic de la Universitat de Ciències Mèdiques d’Isfahan.
Mehrabani-Zeinabad et al. construïren una base de dades que contenia més de 1000 variables, entre característiques bàsiques i clíniques dels participants: característiques socio-demogràfiques, factors cardio-metabòlics, factors d’estil de vida, historial mèdic, etc. D’aquests 1000 variables foren excloses aquelles que mancaven de més del 90% de dades dels participants de la cohort: en restaven 515 variables. D’aquestes variables, n’hi havia 336 completes, 49 variables amb menys del 10% de mancança de dades i 130 variables amb més del 10% de mancança.
Entre les incidència de malaltia cardiovascular entre els participants es considerava l’infart de miocardi, l’atac de feridura, la mort cardíaca sobtada i l’angina inestable. Els diagnòstics eren confirmats per un panell especial integrat per quatre cardiòlegs i un neuròleg. Dels 5.432 participants, el 15,08% (819 participants) patiren algun d’aquests esdeveniments en els setzee anys de seguiment.
Entre els algoritmes d’aprenentatge automàtic utilitzats en aquest estudi hi ha la regressió logística (LR), l’anàlisi discriminant lineal (LDA), l’anàlisi discriminant quadràtic (QDA), SVM, kNN, DT, RF, BART, BARTm, ANN i GBM. La particularitat de BARTm és la capacitat de treballar fins i tot variables de les quals manca més del 90% dels valors.
Les diverses metodologies eren comparades per tal de valorar-ne la precisió, la sensibilitat, l’especificitat i d’altres paràmetres.
Setze anys de seguiment de la Cohort d’Isfahan
En el moment inicial (2001), l’edat mitjana de participants era de 50,49 ± 11,49 anys. El 51,00% eren dones. Els 5.432 participants són classificats segons si en el seguiment patiren alguna malaltia cardiovascular: 819 sí que ho feren.
Els diferents mètodes d’aprenentatge automàtic eren posats a prova de la manera següent. A partir de les dades de base del 2001 havien de poder predir quins dels 5.432 participants patiria en els 16 anys següents algun accident cardiovascular. La major precisió de predicció era de QDA, amb un 75,50% (la pitjor era de DT amb un 51,95%). La major sensibilitat era de DT (82,52%).
Els algoritmes d’aprenentatge automàtic eren comparats amb models estatístics convencionals. Uns i altres mostren que n’hi ha prou amb un nombre reduït de variables (unes vuit) per oferir una predicció ja prou acurada de futurs esdeveniments de malaltia cardiovascular. Caldria centrar els esforços en aquestes variables per reduir la incidència de malaltia cardiovascular d’una simple i efectiva. En el cas concret de la Cohort d’Isfahan les variables més rellevants són l’edat, la pressió sistòlica, el nivell de glucosa en dejuni, els nivells de glucosa postprandial a les dues hores, l’historial de diabetis mellitus o l’historial de malaltia cardíaca. Pot sobtar el fet que no aparegui el consum de tabac en aquesta llista, però Mehrabani et al. recorden que això es pot explicar que el consum de tabac entre les dones iranianes és tan sols del 2,2%.
Les tècniques d’aprenentatge automàtic serien especialment útils per reduir el nombre de variables a considerar. Una vegada s’hagin seleccionat les variables més rellevants, s’hi podrien aplicar models simples més clàssics com LR i DT. BARTm pot ésser especialment útil en estudi de cohort de països en vies de desenvolupament, on el nombre de participants és limitat, i sol haver més dificultats per recollir totes les dades proposades.
Lligams:
Cardiovascular disease incidence prediction by machine learning and statistical techniques: a 16-year cohort study from eastern Mediterranean region. Kamran Mehrabani-Zeinabad, Awat Feizi, Masoumeh Sadeghi, Hamidreza Roohafza, Mohammad Talaei & Nizal Sarrafzadegan. BMC Medical Informatics and Decision Making 23: 72 (2023)
